
Introduction
I was recently bemused by a debate on LinkedIn in which different authors stated their preferred machine learning (ML) model for specific HR tasks. I couldn’t buy into the discussion. ML models are like wines – you should find and use the best one to fit the context! To that end I created the following article to illustrate the way in which you could apply and tune multiple ML models in parallel to determine which model performs best. Why be fixated on one model when you can take the best of a bunch? This article uses the Tidymodels ecosystem to predict wages, using multiple models, applied to a dummy wage dataset from the ISLR package.
Why Predict Wages?
ML models can be used by HR functions to optimise pay levels by predicting wages based on relevant features such as the employee’s experience, education, skills, job role, and performance. This data-driven approach can help ensure that pay levels are fair and competitive, which can in turn help attract and retain talented employees.
Libraries & Data
The provided R code reads a CSV file into a data frame `original_tbl`, cleans the variable names, converts all character variables to factors using `forcats::as_factor()`, changes the ‘year’ variable to a factor, and then deselects the ‘wage’ variable from the data frame.
Code
# data manipulation
library(tidyverse)
# modelling
library(tidymodels)
library(finetune)
library(rules)
# model explaining
library(DALEX) # model explainer
library(DALEXtra) # model explainer with tidymodels functionality
library(modelStudio)
# Processing power
library(doParallel)
library(parallelly)
# Visualisation
library(plotly)
tidymodels_prefer()
original_tbl <- readr::read_csv(file = "dataset-37830.csv") |>
# clean the variable names
janitor::clean_names() |>
# convert all character variables to factors
dplyr::mutate_if(is.character, ~forcats::as_factor(.)) |>
# convert the year variable to a factor
dplyr::mutate(year = forcats::as_factor(year)) |>
dplyr::select(-wage)Data Splits
Here we split the `original_tbl` into a training set and a testing set using the `initial_split` function from the rsample package, which randomly assigns a percentage of data to the training set (default is 75%) and the remaining to the test set. The `set.seed()` function is used twice to ensure the reproducibility of the random sampling process. After splitting the dataset, the code then generates bootstrap resamples from the training set, stored in `pay_folds`.
Code
# Spending the dataset ----
set.seed(836)
pay_split <- initial_split(original_tbl)
pay_train_tbl <- training(pay_split)
pay_test_tbl <- testing(pay_split)
set.seed(234)
pay_folds <-
bootstraps(pay_train_tbl)
# check the pay_folds
# pay_foldsReceipe
The provided R code creates a recipe for preprocessing the `pay_train_tbl` dataset with the target variable `logwage` and all other variables as predictors using the `recipe` function from the `recipes` package in R. This preprocessing includes three steps:
`step_zv` which removes predictors with zero variance,
`step_dummy` which converts all nominal predictors into dummy variables using one-hot encoding, and
`step_normalize` which normalizes the `age` predictor.
Code
normalized_rec <-
recipe(logwage ~ ., data = pay_train_tbl) %>%
step_zv(all_predictors()) |>
step_dummy(all_nominal_predictors(), one_hot = TRUE) |>
step_normalize(age)Model Specifications
The provided R code creates specifications for five different regression models (Random Forest, XGBoost, Cubist, K-nearest neighbors (KNN), and Linear Regression) using the `parsnip` package in R. Each specification indicates the model type, the hyperparameters to be tuned (using `tune()`), the computational engine to be used (like “ranger” for random forest and “xgboost” for XGBoost), and the mode of the model which is set to “regression” in all cases.
Code
rf_spec <-
rand_forest(
mtry = tune(),
min_n = tune(),
trees = 1000) |>
set_engine("ranger") |>
set_mode("regression")
xgb_spec <-
boost_tree(
tree_depth = tune(),
learn_rate = tune(),
loss_reduction = tune(),
min_n = tune(),
sample_size = tune(),
trees = tune()
) |>
set_engine("xgboost") |>
set_mode("regression")
cubist_spec <-
cubist_rules(
committees = tune(),
neighbors = tune()
) |>
set_engine("Cubist")
knn_spec <-
nearest_neighbor(
neighbors = tune(),
dist_power = tune(),
weight_func = tune()
) |>
set_engine("kknn") |>
set_mode("regression")
linear_reg_spec <-
linear_reg(
penalty = tune(),
mixture = tune()
) |>
set_engine("glmnet")Workflowsets
The provided R code first creates a set of workflows that combine a preprocessing recipe (`normalized_rec`) with a list of different model specifications (Random Forest, XGBoost, Cubist, KNN, Linear Regression) using the `workflow_set` function from the `workflows` package in R. It then modifies the workflow set by removing the prefix “recipe_” from the workflow identifiers (`wflow_id`) using the `gsub` function within a `mutate` operation.
Code
normalised_wf <-
workflow_set(
preproc = list(normalized_rec),
models = list(
rf_spec,
xgb_spec,
cubist_spec,
knn_spec,
linear_reg_spec
)
)
normalised_wf <- normalised_wf |>
mutate(wflow_id = gsub("(recipe_)", "", wflow_id))Model Tuning
The provided R code sets up parallel computation, using the `doParallel` package to register multiple cores for parallel computation, and then uses the `tune_race_anova` method to tune the hyperparameters of each workflow in the `normalised_wf` workflow set via the `workflow_map` function; it runs the tuning process across a bootstrap resampling of the training data (`pay_folds`) with a grid of 25 different hyperparameter combinations and stores the results. After the tuning process is finished, it stops the implicit parallel computing cluster with `doParallel::stopImplicitCluster()`.
Code
race_ctrl <-
control_race(
save_pred = TRUE,
parallel_over = "everything",
save_workflow = TRUE
)
doParallel::registerDoParallel(cores = parallelly::availableCores())
fit_wf <- normalised_wf %>%
workflow_map(
"tune_race_anova",
seed = 44,
grid = 25, ## parameters to pass to tune grid
resamples = pay_folds,
control = race_ctrl
)
doParallel::stopImplicitCluster()Assess Model Performance
The provided R code creates a plot using `autoplot` to visualize the performance of the fitted workflows (i.e., models) in `fit_wf` based on the root mean square error (RMSE) metric, selecting the best model, and then adds labels, sets the y-axis limits, removes the legend with `theme`, and finally transforms the static ggplot2 plot into an interactive Plotly plot with `plotly::plotly_build()`. As can be seen from the visualisation the cubist model, a tree ensemble model, performs only marginally better the the xgboost, random forest and linear regression models. Irrespective, the subist model will be used.
Code
model_performance_plot <-
autoplot(
fit_wf,
rank_metric = "rmse",
metric = "rmse",
select_best = TRUE
) +
geom_text(aes(y = mean - .005, label = wflow_id), hjust = 1) +
lims(y = c(0.265, 0.31)) +
theme(legend.position = "none")
plotly::plotly_build(model_performance_plot)Finalise Workflow
This provided R code selects the best performing hyperparameters based on the RMSE metric for the Cubist model from the tuned workflows (`fit_wf`), finalizes the workflow with these parameters, fits it to the original training-testing split (`pay_split`), and then evaluates the metrics of this final model.
Code
best_results <-
fit_wf %>%
extract_workflow_set_result("cubist_rules") %>%
select_best(metric = "rmse")
# best_results
cubist_fit <-
fit_wf %>%
extract_workflow("cubist_rules") %>%
finalize_workflow(best_results) %>%
last_fit(split = pay_split)
collect_metrics(cubist_fit)# A tibble: 2 × 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 rmse standard 0.271 Preprocessor1_Model1
2 rsq standard 0.424 Preprocessor1_Model1Re-assess Final Model
The provided R code creates a scatter plot of the actual versus predicted wage values from the Cubist model (`cubist_fit`), adds a reference line, sets labels, and specifies the x and y axis limits, before transforming the ggplot into an interactive Plotly plot.
Code
predictions_plot <-
cubist_fit |>
collect_predictions() |>
mutate(
`Actual Wage` = exp(logwage) |> formattable::currency(),
`Predicted Wage` = exp(.pred) |> formattable::currency()
) |>
ggplot(aes(x = `Actual Wage`, y = `Predicted Wage`)) +
geom_abline(color = "red", lty = 10) +
geom_point(alpha = 0.5) +
coord_obs_pred() +
labs(x = "Actual", y = "Predicted") +
coord_cartesian(xlim =c(0, 350), ylim = c(50, 200))
plotly::plotly_build(predictions_plot)Model Explainer
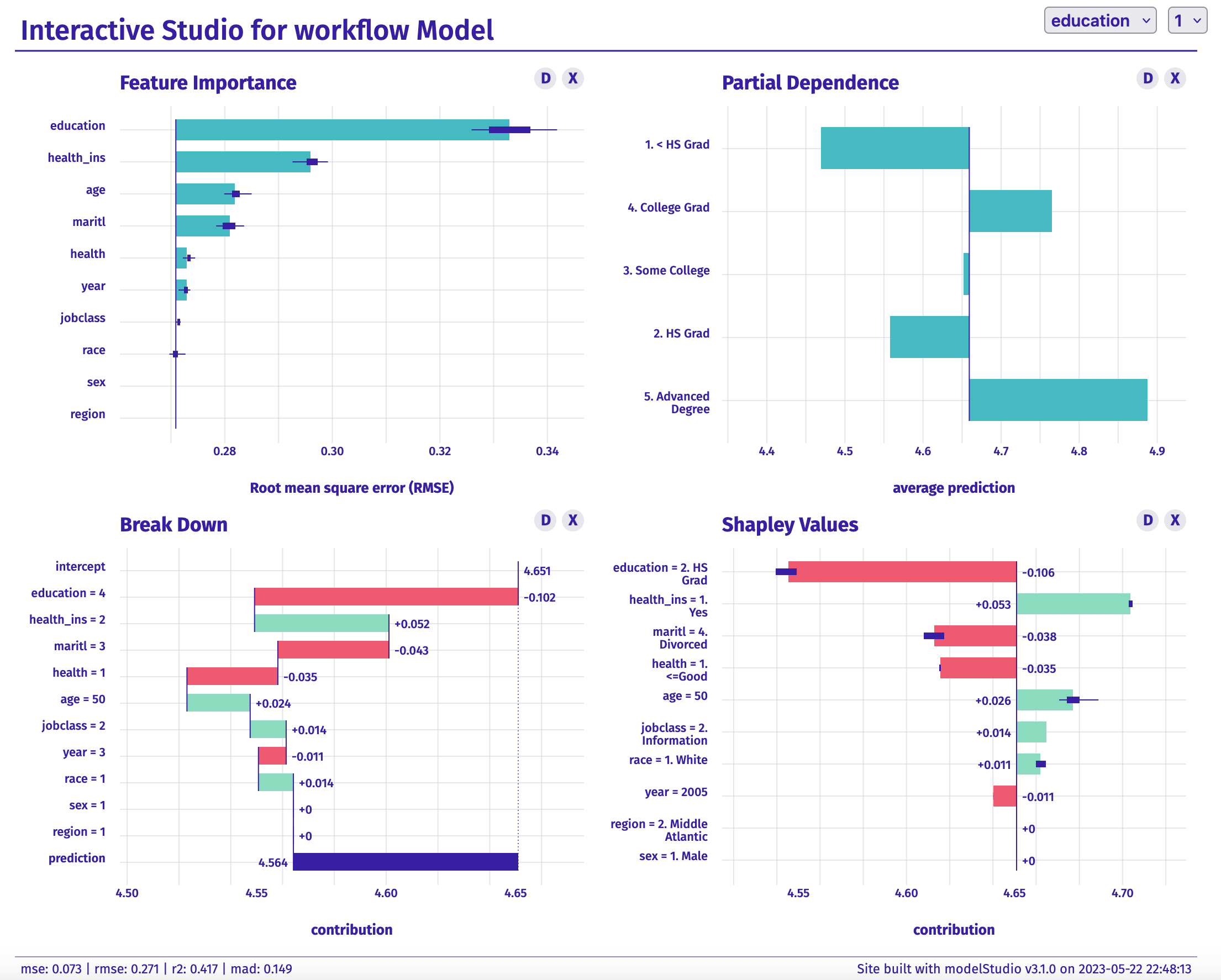
The provided R code first creates an explainer object `pay_explainer` for the final fitted model `final_fitted` using the `DALEXtra::explain_tidymodels` function, using the test dataset `pay_test_tbl` and its `logwage` outcomes. It then displays the model performance metrics with `model_performance`. Following this, it selects two observations from the test data set and assigns them row names. Finally, it uses the `modelStudio::modelStudio` function to create an interactive modelStudio object which provides a comprehensive exploration and explanation of the machine learning model’s behavior for the selected observations.
You can interact with the modelStudio object below. By clicking on the plot name, or the plus button and then the plot name, you can add visualisations to the page. The three additional plots recommended for inclusion are:
- Break Down Plot;
- Shapley Values; and
- Partial Dependence Plot.
For a detailed explanation as to the rationale for inclusion and what the plots signify check out the following article.
Code
final_fitted <- cubist_fit |> extract_workflow()
pay_explainer <- DALEXtra::explain_tidymodels(
final_fitted,
data = pay_test_tbl |> select(-logwage),
y = pay_test_tbl$logwage,
verbose = FALSE
)
# pick observations
new_observation <- pay_test_tbl[1:2,]
# make a studio for the model
modelStudio_obj <-
modelStudio::modelStudio(
explainer = pay_explainer,
new_observation = new_observation,
viewer = "browser"
)
# save the modelstudio object
htmlwidgets::saveWidget(
widget = modelStudio_obj,
file = "model_studio_page.html"
)
Save the model
The model is saved out using the bundle library, which provides a simple and consistent way to prepare R model objects to be saved and re-loaded. This affords users a time saving when saving, sharing and deploying workflows.
Code
# save the model for future use
model_bundle <- bundle::bundle(final_fitted)
readr::write_rds(model_bundle, file = "model_bundle.rds")Conclusion
Machine learning models can be used by HR functions to optimise pay levels by predicting wages based on relevant features, helping to attract and retain talented employees.
Moreover, these models can help reduce bias in pay decisions. By using objective data and transparent algorithms, the influence of subjective or potentially biased factors can be minimized. For example, if the machine learning model does not consider factors such as gender, race, or other protected characteristics, it can help prevent these factors from affecting pay decisions.
The machine learning model’s predictions can also be used to identify potential discrepancies or anomalies in pay levels, which might indicate bias or unfair practices. For instance, if the model predicts a certain pay level based on an employee’s characteristics and performance, but the actual pay is significantly lower, this discrepancy might warrant further investigation. This use case would work particularly well in an environment that embraces transparency.
It’s important to note, however, that while machine learning can be a powerful tool for optimizing pay and reducing bias, it’s not a silver bullet. Care must be taken in selecting and interpreting the features used for prediction, as well as in validating and regularly auditing the model, to ensure fairness and avoid inadvertently introducing new biases.
Reuse
Citation
@online{dmckinnon2023,
author = {Adam D McKinnon},
title = {Using {ML} to {Predict} {Remuneration} {Levels}},
date = {2023-06-01},
url = {https://www.adam-d-mckinnon.com//posts/2023-05-14-predicting_pay},
langid = {en}
}